13001175305 这是一份看似平平无奇的日式便当。

但你敢信,着实每一格食物都是P上去的,而且原图照样酱婶儿的:
背后操作者并不是什么PS大佬,而是一只AI,名字很直白:拼图扩散(Collage Diffusion)。
随便找几张小图拿给它,AI就能自己看懂图片内容,再把各元素异常自然地拼成一张大图——完全不存在一眼假。
其效果惊艳了不少网友。
甚至尚有PS兴趣者直呼道:
这简直是个天赐之物……希望很快能在Automatic1111( Stable Diffusion用户常用的网络UI,也有集成在PS中的插件版)中看到它。

01、为什么效果这么自然?
现实上,此AI天生的“日式便当”尚有好几个天生版本——都很自然有木有。
至于为啥尚有多种版本?问就是由于用户还能自界说,在总体稳固得太离谱的条件下,他们可以微调种种细节。
除了“日式便当”,它尚有不少精彩的作品。
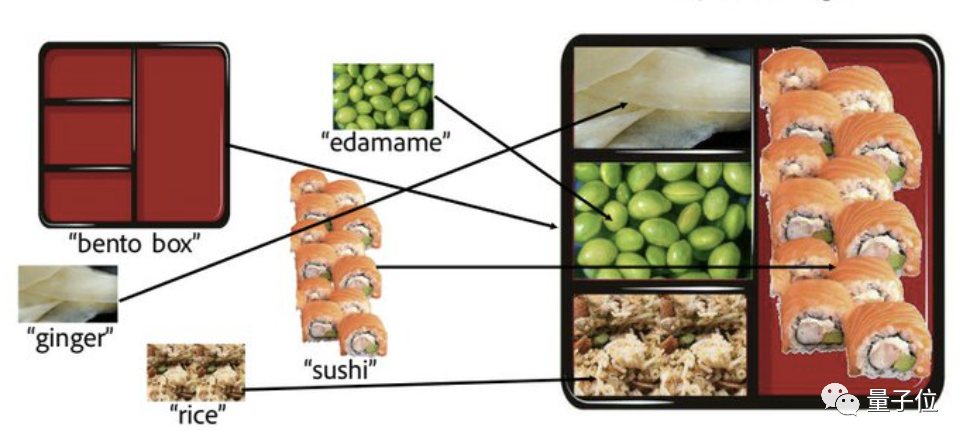
好比,这是拿给AI的素材,P图痕迹显著:

这是AI拼好的图,横竖我愣是没看出什么P图痕迹:

话说这两年,“文字天生图像的扩散模子”着实大火了一把,DALL·E 2和Imagen都是基于此开发出来的应用。这种扩散模子的优点,是天生图片多样化、质量较高。
不外,文字终究对于目的图像,最多只能起到模糊的规范作用,以是用户通常要花大量时间调整提醒(prompt),还得搭配上分外的控制组件,才可以取得不错的效果。
就拿前文展示的日式便当来说:
若是用户只输入“一个装有米饭、毛豆、生姜和寿司的便当盒”,那就既没形貌哪种食物放到哪一格,也没有说明每种食物的外观。但若是非要讲清晰的话,用户生怕得写一篇小作文了……
年入500亿的东莞街边小店
鉴于此,斯坦福团队决议从其余角度出发。
他们决议参考传统思绪,通过拼图来天生最终图像,并由此开发出了一种新的扩散模子。
有意思的是,说白了,这种模子也算是用经典手艺“拼”出来的。
首先是分层:使用基于图层的图像编辑UI,将源图像剖析成一个个RGBA图层(R、G、B划分代表红、绿、蓝,A代表透明度),然后将这些图层排列在画布上,并把每个图层和文字提醒配对。
通太过层,可以修改图像中的种种元素。
到现在为止,分层已经是盘算机图形领域中一项成熟的手艺,不外此前分层信息一样平常是作为单张图片输出效果使用的。
而在这种新型“拼图扩散模子”中,分层信息成了后续操作的输入。
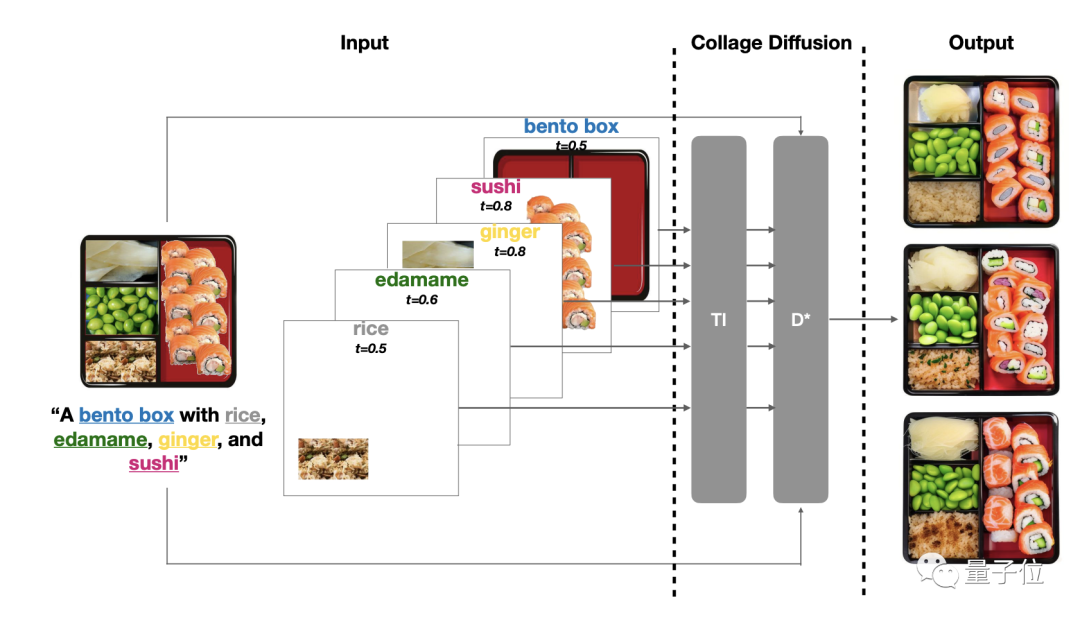
除了分层,还搭配了现有的基于扩散的图像协调手艺,提升图像视觉质量。
总而言之,该算法不仅限制了工具的某些属性(如视觉特征)的转变,同时允许属性(偏向、光照、透视、遮挡)发生改变。
——从而平衡了还原度和自然度之间的关系,天生“神似”且毫无违和感的图片。
操作历程也很easy,在交互编辑模式下,用户在几分钟内就能创作一幅拼贴画。
他们不仅可以自界说场景中的空间排列顺序(就是把从别处扣出来的图放到适当的位置);还能调整天生图像的各个组件。用同样的源图,可以得出差其余效果。

而在非交互式模式下(即用户不拼图,直接把一堆小图丢给AI),AI也能凭证拿到的小图,自动拼出一张效果自然的大图。
02、研究团队
最后,来说说背后的研究团队,他们是斯坦福大学盘算机科学系的一群师生。

论文一作,Vishnu Sarukkai现为斯坦福盘算机科学系研究生,照样硕博连读的那种。
他的主要研究偏向为:盘算机图形学、盘算机视觉和机械学习。
此外,论文的配相助者Linden Li,也是斯坦福盘算机科学系研究生。
在校修业时代,他曾到英伟达实习4个月,与英伟达深度学习研究小组相助,介入训练了增添100M 参数的视觉转换器模子。